KubeCon 2019 上海 CRD 相关 Session 小记
这周借着参加 KubeCon 之名跑到会场划了三天水,最后一天良心发现顿觉需要记录一下,同时也顺带再消化一遍,遂有此文。
整个三天里除了 keynote 之外跑去听得最多的就是大家在 CRD 和自定义控制器上的各种实践,也就是各种 “Operator”。虽然 Operator 本身已经是一种大家司空见惯的模式,但具体如何为生产环境中的
场景与问题定义 CRD 还是一个很有意思的事情。有些设计能够启发我去修正一些以往浅薄的认知,比如蚂蚁的 CafeDeployment 试图去解决的问题让我感受到 k8s 的 API 离”一个好用的 PaaS”还是有距离的;
有些 talk 能在范式方面给我一些启发,比如某个 talk 里提到的多个业务组之间如何基于 CRD 协作;还有一些”意料之外但又情理之中”的设计,让人大开眼界,直呼”我怎么没想到呢?”,比如 OpenCruise 里
的 SidecarSet 。
另外还听了一些偏 ops 的 session 和我司 TiKV 的 session,也有很多收获。但我想写的更聚焦一点,因此就只提一下这些 session 里和 CRD 或自定义控制器有关联的部分。下面就开始吧!
CRD no longer 2nd class thing
第一天傍晚一个专门安利 CRD 的 Keynote。大致内容是讲了一个故事:
(以下内容经过博主个人演绎,我也不知道有没有记岔…)
- sig-storage: 我们想加一个 PV 备份的功能,希望在 k8s 内增加一个内置 API 对象 “VolumeSnapshot” 来描述对一个 PV 的快照。
- sig-architecture: 不同意增加内置对象,请使用 CRD
- sig-storage: 什么!CRD 不是给第三方扩展 k8s 用的吗? 我们现在是要 给 Kubernetes 主干增加功能
然后呢,keynote 里表示 sig-architecture 是对的,CRD 在 Kubernetes 中已经是 “一等公民”,最后带大家入了个门,讲了一下 CRD 的概念,用法以及 kubebuilder。
假如由我来给这个 keynote 一句总结,那就是 Kubernetes 本身都在用 CRD 加新功能了,我们还有啥理由不用吗?
 (一张 slides 的截图)
(一张 slides 的截图)
To CRD or not to CRD
这个 session 虽然叫 “使用还是不使用 CRD,这是一个问题”,最后却没有给出确切的标准来区分某个场景该不该使用 CRD(当然,即使有这样的”标准”,那也是充满争议的)。但这个 session 仍然诚意十足,不仅简明扼要地列出了使用 CRD 需要考虑的问题,还探讨了 CRD 除了扩展 Kubernetes 之外本身的架构意义。这一点让我觉得,很多本身不需要和 k8s 做整合的场景有可能 也可以通过 CRD 放到 k8s 上来做,进而得到一些架构和编程模型上的收益。
先看 slides 里的一个例子,我们有一个微服务体系,分别有 Room、Light、Lock 三个 service:
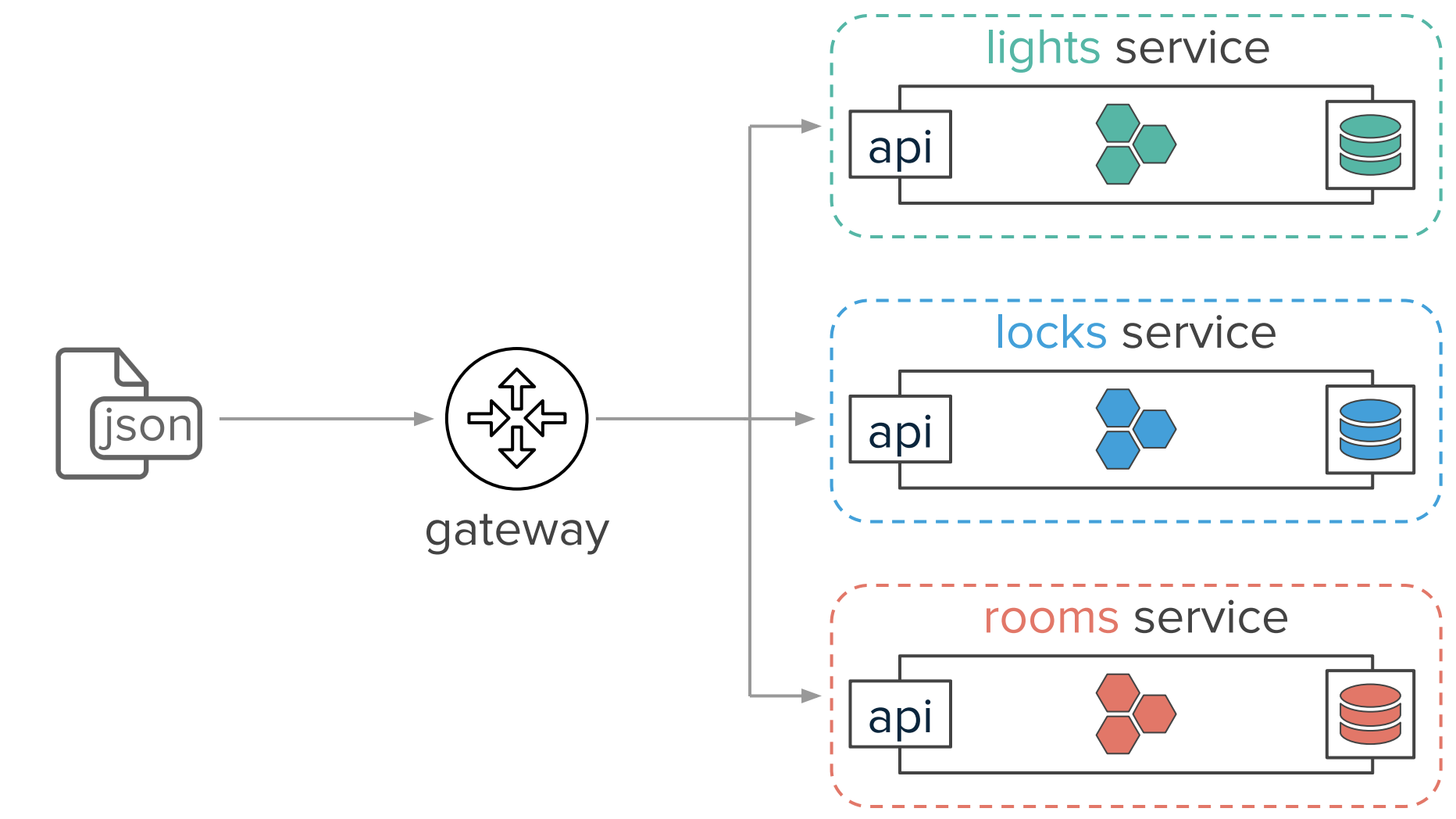
而当用户想打开房间里的某盏灯时,则需要发送一个 Rest 请求:
{
“action”: “switch_on”,
“lights”: [
“lamp-1”,
“lamp-2”
],
“room”: “kitchen”
}接下来一个可能的流程是:
- Room Service 调用 Light Service,打开
lamp-1和lamp-2这两盏灯 - Light Service 打开这两盏灯,更新数据库中等的状态,返回响应给 Room Service
- Room Service 收到影响,更新 Room 对象中灯的亮度
- Room Service 返回响应给用户
这个系统要做好,其实要解决不少问题:
- 每个服务都要解决自己的存储问题:字面意思
- 每个服务都要解决高可用问题:字面意思
- 可靠性问题:个人解读一下,我们发送请求给 Room 服务更新房间,Room 服务再调用 Light 服务打开灯,这时候假如 Light 服务有问题,怎么办?诸如此类的问题最后会需要去做服务间的重试限流熔断这类事
- 服务间的 API 规范:这个大家应该都有感受,每个公司都会制定服务间的调用规范
- 组与组之间围绕 API 的协作:”过程式” 的 API 其实协作起来有很多问题,比如过长的链式调用,循环调用,这些都得通过架构和框架设计去防患于未然
接下来就开脑洞了:我们把这三个 service,全部用 k8s 的自定义 controller 来实现怎么样?
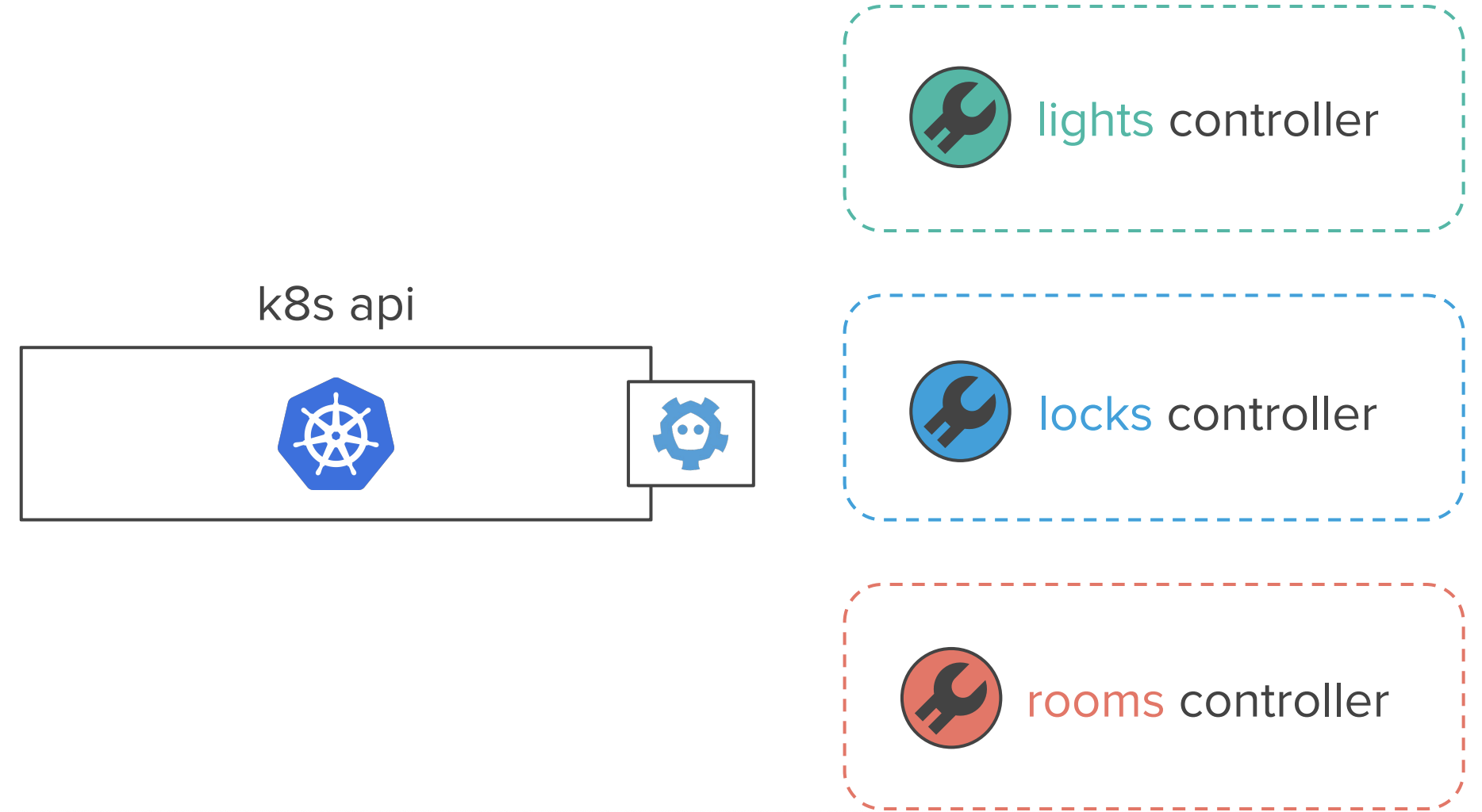
这时候,我们就可以声明式 API 来开灯了:
apiVersion: v1
kind: Room
metadata:
name: kitchen
namespace: default
spec:
lights:
- name: lamp-1
brightness: 0.5
- name: lamp-2
brightness: 1.0接下来的流程就是:
- Room Controller watch 到这个对象的期望状态(spec)变更;
Room Controller 更新对应的 Light 对象的亮度(更新 spec);
apiVersion: v1 kind: Light metadata: name: lamp-1 namespace: default spec: brightness: 0.5 status: currentBrightness: 0Light Controller watch 到
lamp-1和lamp-2这两个对象的期望亮度(spec)发生变化Light Controller 调整这两个灯的亮度,并更新目标对象的
.status.currentBrightnessRoom Controller watch 到两个灯的 status 发生变化,以此为依据更新自己的 status
可以发现整个协作的核心是 k8s 的 api-server,并且所有组件和逻辑都围绕着声明式 API 进行设计。这个设计下:
- 存储问题简化(etcd 解决)
- 高可用问题简化(k8s 部署 3 个 api-server 自然就高可用了,controller 反正随时可以拉起来)
- 可靠性优化(控制循环与声明式 API 这种可以不断自我修正的机制本身就适合解决可靠性)
- 不用考虑 API 规范和 API 协作(自定义控制器基本上就按这个模式写了)
这里要额外解释一下 API 协作,大家可以想象一下,这个例子里用 controller 的方式,协作的心智成本是很低的,我们只需要看一下其它组的 API(也就是 CRD)里的字段含义,然后开始”声明自己要干嘛” 就可以了。
当然,其实这两者的对比是不公平的,因为例子一基本上等于没有框架也没有 PaaS 在裸写应用,而例子二是在现成的架子上搭东西。真正搞开发的时候,底下的数据库,高可用以及由框架或 Mesh 定义的规范与 协作形式基本也都是做完一遍之后开箱即用的,整体成本和自己整一个生产级 kubernetes 孰高孰低还不好说。另外,CRD 虽然改声明方便,但用过 k8s 原生对象的都知道,改 spec 前我们必须得对下面的 机制有所了解,才能明白改了之后到底能否实现自己的需求,因此这个”心智成本”也只是变了一下形式而已。最后,这个”房间、灯、锁”的例子其实选得很好,因为这个系统里组件明确并且都需要去协调一个不可靠的 模块(灯、锁这些设备),假如是我们只是在虚拟账户间转个账对个账啥的,恐怕就很难塞进这个模式里去了。
因此,这是个挺有启发性的例子,但不是一个”安利 CRD”的例子,整体还是非常中立的。
于是乎,Slides 里紧接着就讲了使用与不使用 CRD 的优缺点对比:
- 数据模型受限:etcd 并不是关系型数据库
- 系统整体性能基本取决于 etcd
- 声明式 vs 命令式,没有好不好,只有适不适合
- 团队合作:CRD 很有优势,每个团队提供 CRD 和 controller,可以互相 watch 对方的 API 对象
当然了,到底用不用 CRD 还是取决于个人理解的,只是不要忘了(Slides 的最后一页):
CafeDeployment
这个 talk 的中文题目是”为互联网金融关键任务场景扩展部署”,相当…不知所云,假如不是看了眼英文名”Extending Deployment for Internet Financial Mission-Critical Scenarios”, 我差点错过了这个精彩的 session…
Session 的主角是 CafeDeployment,后来看到在 KubeCon 前几天蚂蚁的公众号就发文章讲了这个东西,大家可以直接前往 原文 看看它解决的问题和具体的技术场景,假如觉得太长不看,也可以看下面的 三个 Key Takeaways:
CafeDeployment是一个顶级对象,就像 Deployment 管理 ReplicaSet 一样,CafeDeployment下面管理一个叫做 InPlaceSet 的对象。CafeDeployment的职责主要是按照策略 *在多个机房内各自创建一个 InPlaceSet*,来做容灾,同时提供部署策略的控制,比如现场演示的就是新版本分三批发布,每批升级中间需要手工确认(改 Annotation)- InPlaceSet 提供了 Pod 本地升级的能力(实现细节没讲,但是要 PoC 的话其实在 Controller 里依次修改 Pod 的镜像就行,修改后 Pod 里的容器会 Restart 使用新镜像,Pod 并不会重建)
- 用 Readiness Gate 控制了 Pod 本地升级时的上下线过程。大体就是通过设置 readiness gate 为 true 或 false 来设置 Pod 的状态是否为 Ready,从而协调 endpoints,具体逻辑可以看原文
一开始听这个 session 的时候,讲需求的时候说现在的策略无法满足跨机房高可用部署、无法实现优雅升级我其实是很疑惑的:这不是 anti-affinity 以及 preStopHook + readinessGate 就能实现了吗?
听到 demo 和实现部分才知道, CafeDeployment 的跨机房高可用部署是指均匀分布在多个机房中,并且分批升级时每次要从多个机房中选择一部分进行升级,以实现全面的灰度验证;而原地升级的特性也没法自动
摘干净流量。对这些实际业务需求的梳理和展示其实是这个 session 给我最大的收获。
还有几个比较有意思的事情:
CafeDeployment用一个 annotation 来控制升级过程中的手动确认:升级完一个批次后,annotation 被置为false,用户修改为true后继续开始下一批次的升级。其实我本来觉得这个做法不符合声明式 API,status 和 spec 是对不上的,像 statefulset 这样用 paritition 更合理。但这种办法也有好处,就是用户界面最简化,用户只需要关心是否能继续升级即可,这里也是一个权衡;CafeDeployment没有用 CRD,而是用 AA (Aggregated ApiServer)实现的。原因是 CRD 不能定义/scale这样的 subresource,另外,听说CafeDeployment也正在打算把自定义的 APIServer 的存储换掉,不用 etcd;
Alibaba CloudNative
也就是”电商巨头的原生云迁移经验”这个 session,张磊老师的 session 是一定要去听的 —— 当然,还有几百个小伙伴也都是这么想的,因此在开始前 10 分钟 Room 609 就直接出现了爆场,外面的小伙伴都进不来 的情况,火爆程度可见一斑。事实上内容也确实是干货满满。
记得 KubeCon 听到的 talk 里,阿里似乎还在说 “把 Sigma 的 Control Plane 换成 Kubernetes”,而这次的架构图就已经直接是 Kubernetes 原生 ApiServer + 一个完全自研的 Scheduler + 自研 Controllers (Cruise)了,Pouch 也换成了 containerd。session 里还着重说了消灭富容器,全面拥抱了社区的最佳实践,阿里这样的体量展现出如此敏捷的技术升级,当时在会场听的时候确实是很震撼。
另外要说的一点是,关于最佳实践的文档和博客我们大家都常常看,但真正要去讲给别人的听,要用最佳实现说服别的人的时候,却总是感觉讲不生动,词不达意,最后讲来讲去变成复读机 “这是最佳实践,这是最佳实践…” 而张磊老师讲的时候总是能恰到好处地”我举个例子”一波讲明白,这个姿势要能学来可就不得了了…
还有一个重头是 OpenCruise,提供三种 CRD:SidecarSet,(Advanced)StatefulSet,BroadcastJob,具体的作用大家看一下项目文档就能了解个大概。我想写的还是一些体会。
首先是 OpenCruise 里的 StatefulSet 提供的原地升级功能。我原本以为原地升级不就是保持 IP 不变吗,这不就是迁就虚拟机时代的基础设施吗,一点也不云原生。当然,你让我说为什么不支持原地升级,我也讲 不明白,可能只会说 Pod 的设计意图就是 Mortal 的,你们现在逆天而为要给 Pod 续命实在是搞得太丑了。事实证明我完全错了,这些认知根本是没有见过实际的业务场景在意淫(还好我还晓得参加 KubeCon)。 讲师之一的酒祝讲了个例子,阿里自研的调度器支持 Batch Scheduling,对于一批十几万个 Pod,可能要尝试非常多种方案才能得出一个排布拓扑,这时候再去做删除式的滚动升级代价太大了;同时,类似双十一 这样的大促之前还要搞全链路压测,压测完之后要是一个滚动拓扑变了,系统承压量又不一样了怎么办?
这个例子说服力超强,而且也凸显出本地升级”稳定为先”的优势。
然后是 SidecarSet,与 session 前半部分的内容结合来看,这个也是符合去富容器历史进程的产物。因为大量富容器中的非业务进程需要做成 sidecar,而把 Sidecar 和业务容器的管理剥离开始,则是一个 四两拨千斤的创新,不说了不说了…我都感觉快成软广了(其实是写不动了 orz)
总之,假如你没去听的话,看一下 slides 绝对值得。
结语
上面的各种 session 再结合 KubeCon 前几天发布的 Kubernetes 1.15 对 CRD 的大量增强以及社区里俯拾皆是的 xxx-operator,无疑印证了 CRD 和自定义控制器已经是最 “稀松平常” 的 Kubernetes 扩展模式。这时候,CRD 本身也就不再有意思,需要把光彩让给 SidecarSet, CafeDeployment 这些匠心独运的业务实践了。另外,要插个硬广,我司在做的 tidb-operator 面临的场景同样极富挑战,假如你想知道在云上编排一个复杂的分布式数据库是一种怎样的体验,欢迎通过邮箱 [email protected] 联系我!